2026-05-13
一个人用 AI,和一组 AI 帮你互相审稿,差距太大了
你让一个 AI 帮你判断一个创业点子。 它会说得很完整。 目标用户、商业模式、MVP、风险点,全都有。 问题是,你看完会有一种错觉。 好像它真的想明白了。 但复杂问题最怕的就是这个。 一个模型给你的答案越顺,你越容易忽略里面没暴露出来的漏洞。 写文章也是一样。 一个模型能写出很顺的初稿,但标题可能没点击欲,开头可能没…
单个 AI 的答案太顺了
你让一个 AI 帮你判断一个创业点子。
它会说得很完整。
目标用户、商业模式、MVP、风险点,全都有。
问题是,你看完会有一种错觉。
好像它真的想明白了。
但复杂问题最怕的就是这个。
一个模型给你的答案越顺,你越容易忽略里面没暴露出来的漏洞。
写文章也是一样。
一个模型能写出很顺的初稿,但标题可能没点击欲,开头可能没钩子,事实边界可能有坑。
写代码也一样。
一个模型能把功能写出来,但它可能只看了局部,没注意旧项目里的隐藏约定。
所以复杂任务不要只问一个 AI。
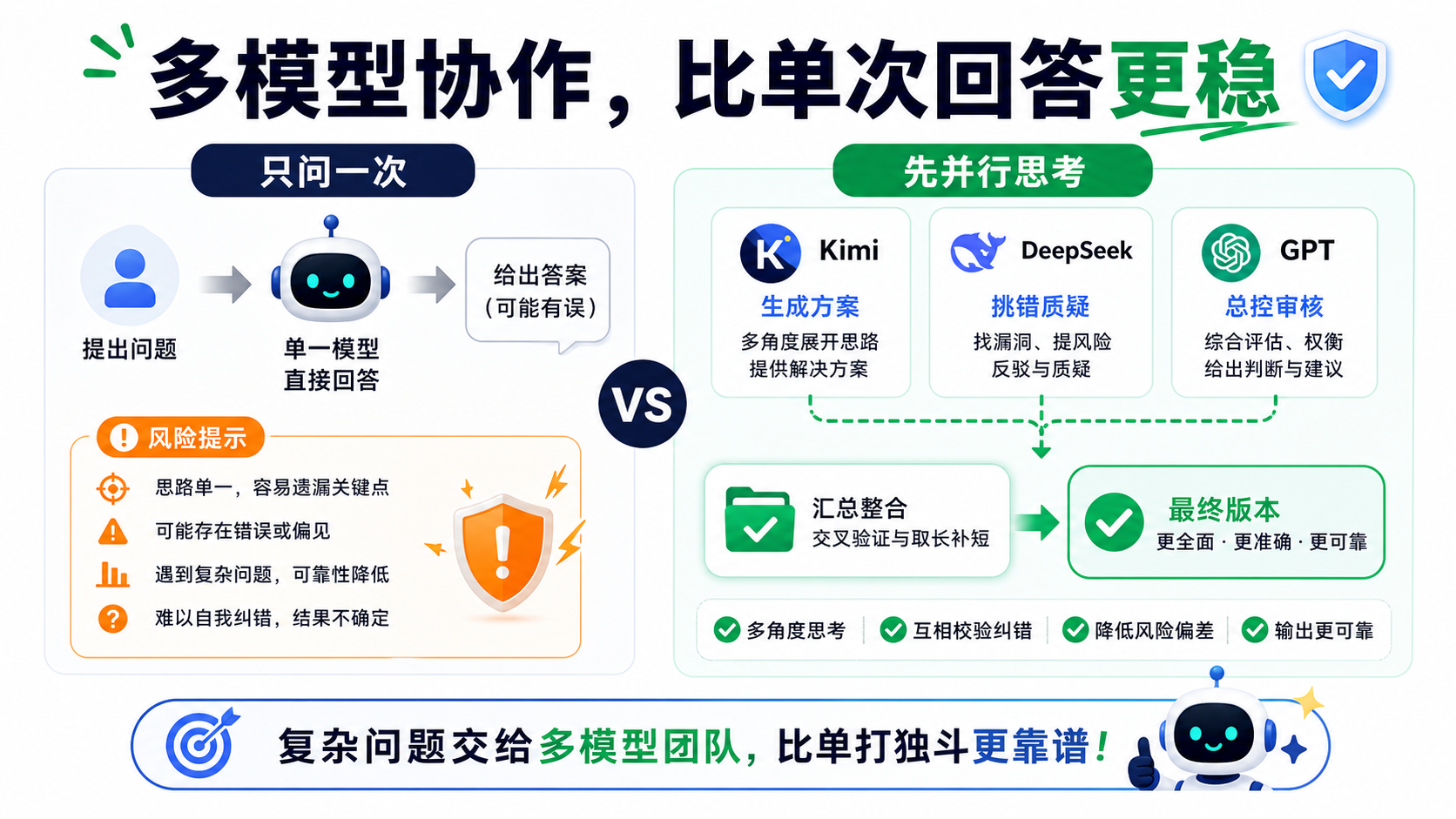
更稳的办法,是让几个 AI 先各自想一遍,再让一个主模型做综合。
最近 arXiv 上有篇论文叫 HeavySkill: Heavy Thinking as the Inner Skill in Agentic Harness,提交时间是 2026 年 5 月 4 日。
先分头想,再统一判断
它里面有个很实用的思路,复杂任务可以先做多路并行推理,再做总结。
换到日常使用里,就是先分头想,再开会。
这个思路其实我们现在就能用。
普通人也该学会调度 AI
比如写一篇长文章。
不要让一个模型从选题、起稿、审稿、改写一路包到尾。
你可以让 Kimi 先从读者角度看标题和开头。
让 DeepSeek 从事实风险和逻辑漏洞角度审一遍。
让 GPT 或 Codex 做总控,决定哪些意见采纳,哪些意见扔掉。
最后再统一改成一版。
这比单模型自写自审靠谱得多。
因为模型会犯不同的错。
写得顺的模型,不一定会挑事实漏洞。
会挑代码边界的模型,不一定懂读者情绪。
擅长读仓库结构的模型,不一定适合拍最终方案。
让它们分工,价值就出来了。
代码任务也一样。
一个模型负责读仓库,找调用关系。
一个模型负责写第一版实现。
一个模型专门看测试和边界。
主模型最后做判断,避免把局部正确的改动直接放进项目里。
这不是为了把流程搞复杂。
恰恰相反,它是为了把复杂问题拆成几个更稳的判断。
有些任务最适合这么做。
产品判断。
比如这个想法值不值得做,目标用户是不是真的痛,MVP 该怎么切。
长文章。
标题、开头、结构、情绪、事实边界、转化入口,每一层都可能出问题。
代码修改。
尤其是老项目,最怕模型只看局部,改完能跑,却把隐藏约定撞坏。
商业决策。
只听一个模型,很容易被它写出来的确定感骗过去。
我现在越来越觉得,普通人用 AI 的差距,不只在于谁更会提问。
更在于谁会调度一组 AI。
让它们互相挑错,互相补位,最后为你服务。
单个 AI 是工具。
一组 AI 经过分工和审查,才开始像团队。
写在最后
以后会用 AI 的人,差距不只在于谁更会提问。
更大的差距,是谁能让不同模型各干各的活,再用审查把结果压稳。
单个 AI 是工具,一组 AI 经过分工和审查,才开始像团队。
我是麦总玩 AI,长期实测 AI 工具、Agent 工作流和普通人能直接用起来的提效方法。
如果你也想少踩坑,点个关注,后面继续拆。